
Audio preprocessing
Viele Projekte in dem Bereich Machine Learning haben mit der Bilderkennung zu tun, doch wie geht man mit Audiodaten um?
Digitale Audioverarbeitung
Schallwellen sind kontinuierliche periodische Varianzen des Luftdrucks und können deswegen durch die Mathematische Analysis betrachtet werden, da es sich um analoge Signale handelt. Aber um auf Computern damit arbeiten zu können müssen diese Signale erst digitalisiert werden, von kontinuierlichen Schallwellen auf eine Liste diskreter Zahlen. Das wird gemacht indem man den absoluten Wert des Signals in regelmäßigen Abständen misst. Dieser Prozess nennt sich "Sampling". Dafür wird eine Sampling Rate (Hertz) ausgewählt und die Intensität an jedem Punkt gemessen. Durch eine höhere Sampling Rate verbessert sich die Qualität, aber auch die Dateigröße. Nach dem Sampling müssen diese Werte konvertiert werden um in einen bestimmten Bereich zu passen. Mit einem 16-bit Signal kann ein Wert zwischen -32768 und 32767 dargestellt werden, jedoch können dadurch Signalinformationen verloren gehen. Wird eine höhere Anzahl an Bits verwendet, steigt die Spanne zwischen leisester und lautester Lautstärke die abgebildet werden kann. Dieser Dynamikumfang wird auch mit Dezibel(db) angegeben.
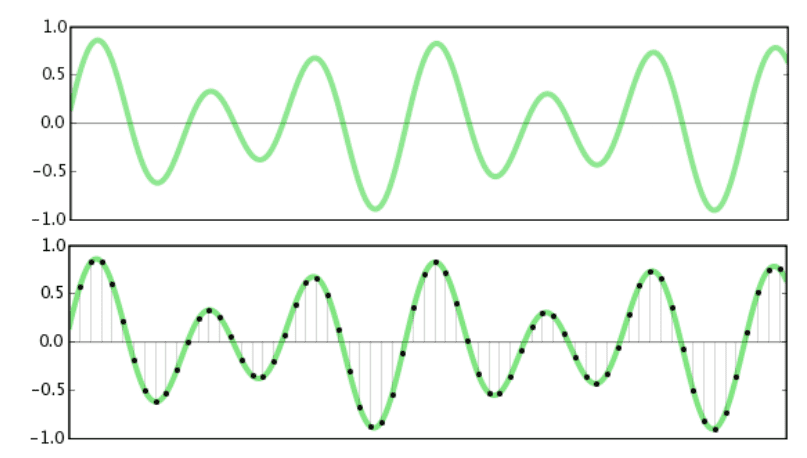
Auf dem Bild kann man erkennen, dass je mehr Einzelwerte gemessen werden, desto detailreicher wird die Digitalisierung.
Audiodateien können in diversen Formaten, Sampling Rates und Dynamikumfang vorliegen. In einem python Projekt kann die library LibROSA eingesetzt werden, um mit Audiodaten unterschiedlicher Art gleichzeitig zu arbeiten, z.B. wav, flac und mp3. LibROSA nutzt dafür selber die "audioread" library die bereits installierte Codecs nutzt um mit unterschiedlichen Formaten umgehen zu können. Wenn LibROSA eine Datei einliest, wird diese standardmäßig übersetzt in eine Audio Zeitreihe als ein numpy Array und konvertiert zu einem 22.05KHz mono Track mit 16bit (96dB). Diese Werte eignen sich zum Beispiel für Musik und Sprachinhalte da das menschliche Gehör Frequenzen zwischen 20Hz und 20000 Hz wahrnehmen kann und bis zu einem Dynamikumfang von 90dB. Diese Zahlenreihe kann auch als Bild visualisiert werden in einem Spektrogram. LibROSA Spektrogramme werden als zweidimensionale numpy Arrays generiert mit der ersten Achse für die Frequenz und die zweite als Zeitachse.
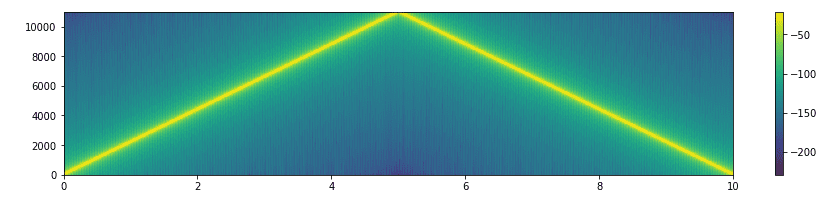
In diesem Spektrogramm wird zum Beispiel ein steigender und fallender Sinuswellenton dargestellt.
Feature Extraktion
Da rohe Audiodaten für manche Problemfälle redundante Informationen enthalten, können manche Arten der Feature Repräsentation genutzt werden um nützliche Informationen im voraus zu extrahieren. Auch in diesem Schritt kann Machine Learning eingestzt werden, im sogenannten "Feature Learning". Diese Features können dann in ML Modellen oder anderen klassischen Algorithmen eingesetzt werden.
Es existieren zwei Herangehensweisen was Feature Extraktion betrifft. Man kann entweder die unbearbeiteten Daten und das Modell selber eine interne Repräsentation der Daten lernen lassen oder man bearbeitet die Daten im voraus. In diesem Fall ist Expertenwissen nötig um zu bestimmen welche Aspekte der Daten für das Problem relevant sind. Die Herangehensweise die unverarbeiteten Daten zu nutzen kann Probleme verursachen, wenn die Daten sehr heterogen sind, zum Beispiel unterschiedliche Formate, bit rate, sample rates, Längen der Aufnahmen, etc. Manche dieser Unterschiede können leicht behoben werden indem man alle Daten transformiert um das selbe Format zu besitzen.
Mel Frequency Cepstral Coefficients
Mel Frequency Cepstral Coefficients (MFCCs) sind Features die seit den 70ern häufig in der Spracherkennung eingestzt werden. Mel (von Melody) bezeichnet eine Einheit die der wahrgenommene Tonhöhe entspricht. Die Mel Skalierung setzt den von Menschen wahrgenommenen Ton in Relation zur tatsächlichen Frequenz. Da das menschliche Gehör kleine Unterschiede im tiefen Frequenzbereich besser unterscheiden kann als im hohen Frequenzbereich, passt diese Skalierung die Intensitäten der menschlichen Wahrnehmung an und reduziert die Bandbreite der Tonstufen.
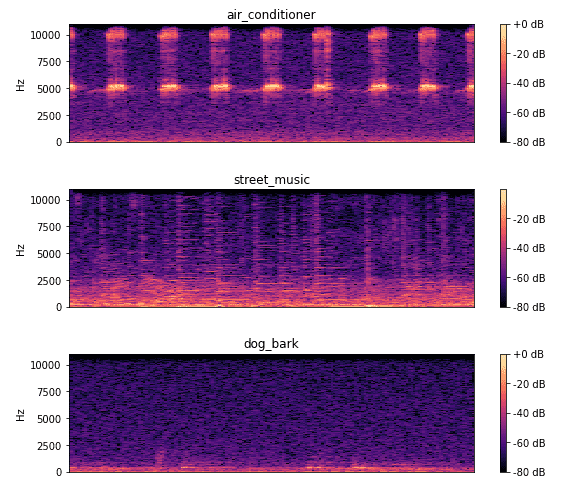
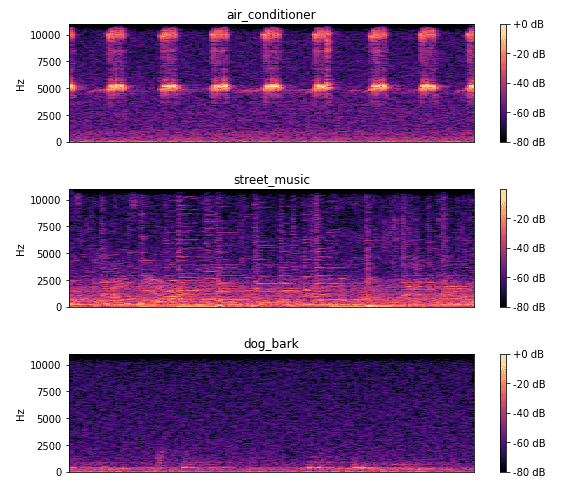
In diesem Bild kann man herauslesen, dass eine Klimaanlage in einem regelmäßigen Rhytmus arbeitet. Bei der Straßenmusik sind verschiedene diskrete Über- und Untertöne erkennbar. Das Hundegebell ist nicht stark ausgeprägt, da die Aufnahme einen Hund in der Ferne darstellt.
Diese Visualisierung von Geräuschen erlaubt es einem auch mit Bilderkennungsmethoden Audioanalysen durchzuführen. Aber was ist der Vorteil davon Bilderkennungsmethoden für Audiodaten einzusetzen? Die Bilderkennung ist eines der am besten entwickelten Felder was ML angeht. Die Erkentnisse aus diversen Feldern wie autonomes Fahren, Satellitenbilder Analysen, medizinische Bildgebung usw. sind übertragbar aufeinander und auch auf die Audioanalyse.
Fazit
Mit Machine Learning werden viele neue Anwendungen mit Audiodaten möglich, von der Spracherkennung und Erzeugung, über die Maschinenwartung hin zu allgemeinen Klassifizierungen. Die Audiodaten vor dem Training von Sequenzen zu Bildern von Spektrogrammen umzuwandeln, eröffnet einem dabei neue Anwendungsmöglichkeiten.
Bei Fragen und Anregungen bin ich erreichbar unter james.friesen@pixel.de




