Das Thema Event Sourcing (ES) hat mich während meiner Masterarbeitet begleitet und wurde im Laufe der Arbeit immer mehr zum Kernaspekt. Allerdings sind viele Konzepte und Herangehensweisen deutlich anders als die sonst üblichen Architektur Ansätze. Aus diesem Grund soll dieser Artikel als kleine Einführung in die Thematik dienen.
Motivation
Im Gegensatz zu herkömmlichen Softwaresystemen wird beim Event Sourcing nicht der Zustand verschiedener Entitäten abgespeichert, sondern die Liste oder Historie an tatsächlich vorgefallenen Ereignissen bzw. Events. Das bedeutet vor allem für Domänen die von der Nachverfolgbarkeit bzw. der Änderung des Entitäts-Zustands profitieren einen großen Vorteil.
Dadurch dass jede Veränderung am Zustand mit einem Event einhergeht, können diese Änderungen leichter nachvollzogen und interpretiert werden. Außerdem können durch die nicht Veränderbarkeit der Events vergangene Zustandsmodelle zu jeder Zeit wieder dargestellt werden. Dies erlaubt Analysen zu jedem beliebigen Zeitpunkt und kann hilfreich sein, bei der Frage nach den verschiedenen Ursachen für einen Zustand.
Vergleich zu REST
Bevor wir uns in die Tiefen von Event Sourcing stürzen, sollten wir uns einen "gängingen" Architektur-Ansatz anhand einer REST-Spezifikation noch einmal vergegenwärtigen. In einer solchen Welt werden die Zustände von Entitäten in einer Datenbank (DB) abgespeichert bspw. die Anzahl an Items in einem Warenlager. Nun wird sich dieser Zustand, durch vom Anwender ausgelöste Aktionen, verändern bspw. wenn jemand eines dieser Items bestellen will. Hierbei ist zu beachten, dass eine Anfrage am Server als gekapstelte, atomare Aktion betrachtet wird. Alle für die Operation notwendigen Parameter sind in der Anfrage enthalten. Nachdem die entsprechende Funktion im Back-End durchgeführt wurde, wird der daraus resultierende Zustand in der DB abgespeichert und an die ursprüngliche Anfrage ausgeliefert.
Event Sourcing
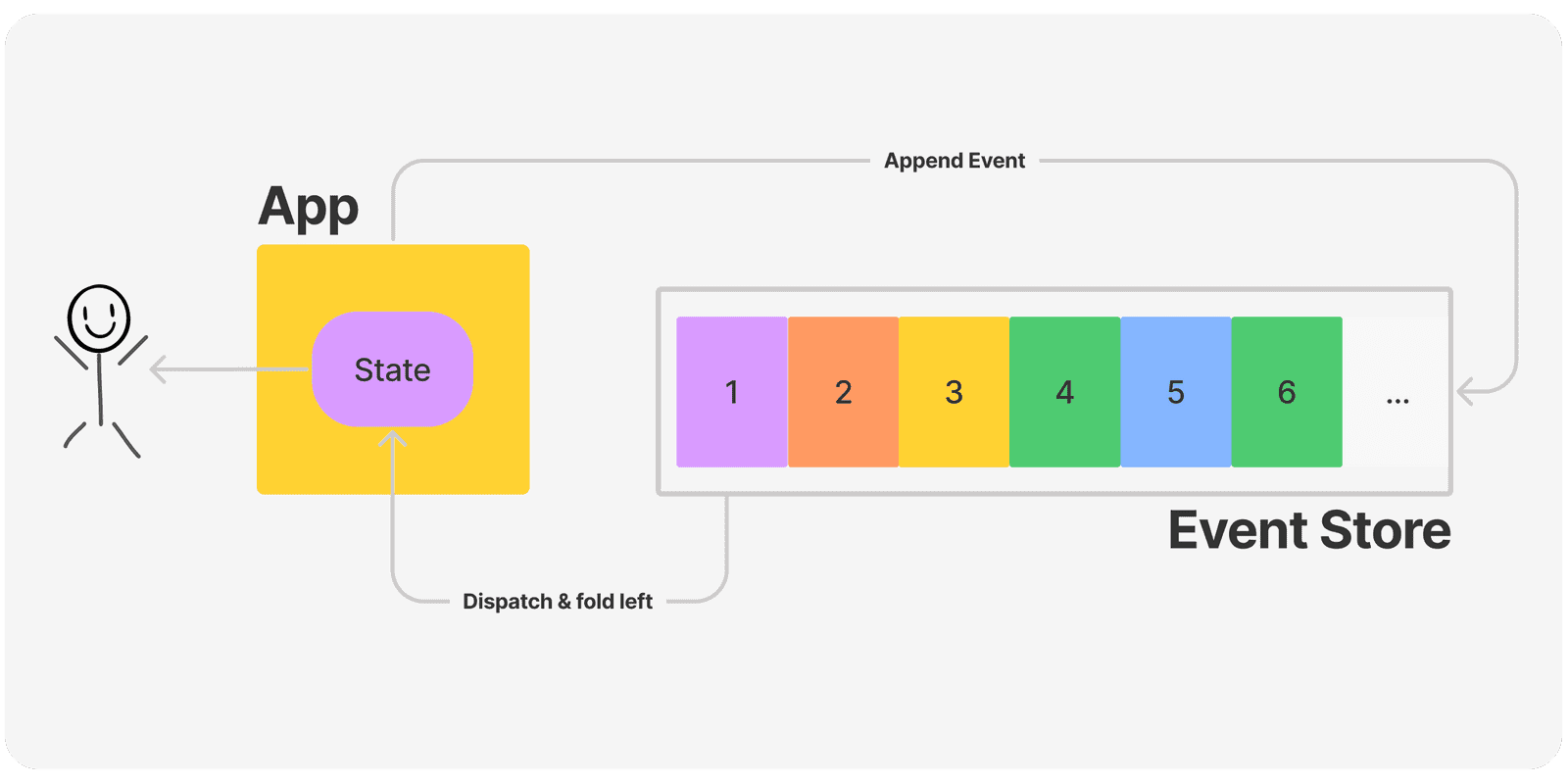
Im Gegensatz zum eben beschriebenem Vorgehen, wird beim Event Sourcing eine Sequenz aus nicht veränderbaren Ereignissen in einem Daten-Stream abgelegt.
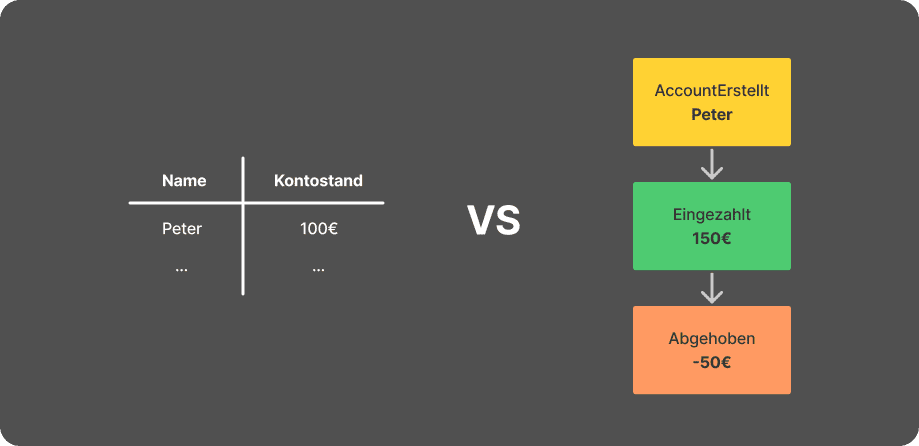
Das Bild stellt auf der linken Seite den DB-Eintrag aus einer wie vorher beschriebenen Architektur dar. Dabei wird nur der aktuelle Wert des Kontos geführt, wobei auf der rechten seite das Event Sourcing Äquivalent aufgeführt ist. In diesem Ansatz wird zuerst ein "Konto eröffnet"-Event benötigt. Anschließend wurde der Wert "150" beim Event "Einzahlung" übergeben. Schlussendlich gibt es noch ein "Auszahlung"-Event mit dem Wert "50" woraus sich der Kontostand "100" errechnen lässt.
Dieses simple Beispiel verdeutlicht allerdings bereits den Kerngedanken von Event Sourcing.
Jede Änderung am Anwendungszustand wird durch ein Event-Objekt festgehalten. Diese Events werden in der Reihenfolge wie sie aufgetreten sind, anschließend in einer Sequenz abgespeichert.
Um die Idee von ES weiter zu vertiefen, werden wir nun die verschiedenen Teilaspekte dessen betrachten.
Data Models
Data Models sind Zustandsmodelle die aus der Berechnung mehrer Events hervorgehen. Aus dem vorherigen Beispiel wäre ein denkbares Data Model mit dem Konto Objekt von "Peter" und dem Kontostand "100" angelegt. Neben dem eigentlichen Event muss man jedoch auch immer dessen Offset betrachten. Der Offset ist die Stelle im Daten-Stream an dem das Event aufgetreten ist.
Diese Data Models können dann im Hauptspeicher des Servers gehalten werden um ankommende Anfragen möglichst schnell zu beantworten. Um den Speicher des Servers nicht zu überlasten, wären in einer realen Anwedung weitere Mechanismen nötig, welche die Data Models automatisch nach einer gewissen Zeit bereinigen. Falls eine Anfrage auf ein Data Model zugreifen muss, das bereits gelöscht wurde, wird der Stream von vorne gestartet und das DM neu berechnet. Auch hier sieht man wieder einen klaren Unterschied zum REST-Gedanken, bei dem ein zustandloses Server-Modell angestrebt wird.
Snapshotting
Snapshotting ist ein Mechanismus, bei dem ein Data Model zusammen mit dem für ihn gültigen Offset zu einem gewissen Zeitpunkt serialisiert und abgespeichert wird. Anschließend kann bei einer Anfrage geprüft werden, ob es für das angefragte Data Model bereits einen Snapshot gibt. Dieser wird anschließend geladen und die Event Sequenz wird auf den Offset gesetzt der durch den Snapshot spezifiziert ist.
In meiner Masterarbeit wurde dieser Mechanismus implementiert (Snapshots wurden als JSON-Datei auf dem Server gespeichert). Anschließend habe ich untersucht, wie lange es dauert bis ein Data Model vollständig von der Client-Anwendung berechnet wurde im Gegensatz zur Auslieferung und Instansziierung des Snapshots.
| Anzahl Events | 500000 | 1 Million | 2 Millionen |
|---|---|---|---|
| Berechnungszeit ohne Snapshot | ~1.6 Min | ~2.6 Min | ~4.7 Min |
| Übertragung + Laden Snapshot | 302 Ms | 299 Ms | 301 Ms |
Es fällt sofort auf das die Berechnungszeit bzw. die Zeit welche die Client-Anwendung benötigt um alle n Events zu erhalten und dabei zu verarbeiten (in etwa) linear ansteigt. Darüber hinaus ist die Zeit um einen Snapshot zu instanziieren bedeutend kleiner und konstant. Auch wenn dieses Beispiel keine Fachlichkeit beinhaltet, soll es verdeutlichen wie wichtig ein Snapshotting-Mechanismus bei der Anfertigung einer Event-Sourcing-Anwendung ist.
Audit Log
Ein weiterer Vorteil von ES ist der Audit Log, der schon fast "frei Haus" durch die Architektur entsteht. Alle Events werden in einer nicht veränderbaren Sequenz abgespeichert. Eben dieser Daten-Stream eignet sich deshalb perfekt als Audit Log.
Er kann leicht kopiert und in einer Debug-Umgebung verwendet werden. Außerdem können künftige Features oder vorhandene Bugs gut damit untersucht werden, da die Art und Weise wie dieser Stream durchlaufen wird (einmal alle Events von Anfang bis zum Ende) deterministisch ist.
WORM
Das die Events und der Daten-Stream zwingend nicht veränderbar sein sollen, wurde bereits mehrmals erwähnt. Diese Tatsache sollte auch durch entsprechende Hardware unterstützt werden. Hierfür gibt es spezielle Write once Read many Festplatten, welche auf Hardware-Ebene eine Veränderung der Daten verhindern.
Die Folgen wenn die Festplatten eine nachträgliche Änderung der Events zulassen, können anhand des 2002 Sportwetten Skandals gut nachvollzogen werden. Hierbei wurden Software-Events von einem Entwickler so manipuliert, dass dieser als Gewinner bei dem jährlichen Sportwetten Ereignis "Breeders Cup" gezogen wurde. Dadurch gelang ihm (und seinen Freunden) ein Raubzug von 3 Millionen USD. Tatsächlich erregte dieser Vorfall nur das Misstrauen der Behörden, da die manipulierte Wette eine 43:1 Chance hatte und die einzig plazierte in den ganzen USA war. Andernfalls wäre dieser Vorgang u.U. gar nicht weiter untersucht worden.
Event Store
Das die Events in der Reihenfolge in der sie auftreten, abgespeichert werden müssen, wurde bereits mehrmals erwähnt. Doch welche Technologien eignen sich überhaupt als Event Store ?
Grundsätzlich lässt sich ein Event Store mit jeder Datenspeicherung umsetzen.
Auch eine SQL-DB kann einfach nur eine Tabelle enthalten, die dann so konfiguriert ist keine Änderungen sondern nur hinzufügende und lesende Zugriffe zu erlauben. Es gibt natürlich trotzdem Technologien deren Datenspeicherung bereits als Sequenz organisiert ist, weshalb sich diese besser als Datenspeicher eignen. In meiner Masterarbeit habe ich Apache Kafka dafür verwendet, aber auch andere Tools wie Event Store oder Apache Cassandra sehen für Event Sourcing besonders geeignet aus.
Eventual Consistency
Eine weitere Thematik die beim Event Sourcing nicht außen vorgelassen werden sollte ist die Eventual Consistency. Bei der Darstellung eines Data Models weiß die Client-Anwendung nicht, ob bereits ein neues Event aufgetreten ist, welches das aktuelle Data Model beeinflussen wird. Dies hat zur Folge, dass stetig mit einem Update des Modells gerechnet werden muss. Außerdem werden Entscheidungen die basierend auf dem alten Datenmodell getroffen werden, möglicherweise von an der Anwendung abgelehnt und die UI anschließend geupdatet. Um diesen Mechanismus etwas besser zu verstehen, könnte man sich ein Szenario vorstellen, in dem ein Anwender eine Ware bestellen will. Einen kurzen Moment bevor er die Bestellung tätigt, wird allerdings das letzte Item von einem anderen User gekauft. Für ein kleines Zeitfenster ist die Anwendung vom ersten Anwender noch nicht darüber informiert, dass ein neues Event aufgetreten ist. Allerdings wird der Server anschließend beim Bestellvorgang die Quantität im Lager prüfen und den Anwender informieren, dass die Ware leider nicht mehr verfügbar ist. Dieser Umstand ist keineswegs ein Ausschlusskriterium für Event Sourcing sondern bedeutet lediglich, dass die Anwendung anders konzipiert sein muss und die Entwickler berücksichtigen, dass sich Data Models zu jedem Zeitpunkt ändern bzw. veraltet sein können.
Fazit
Event Sourcing bringt den Vorteil der Nachvollziehbarkeit von Änderungen mit sich. Des Weiteren ist ein System, dass Daten niemals vergisst in einem Zeitalter in dem sich alles um Daten zentriert aus wirtschaftlicher Sicht interessant. Allerdings müssen auch einige Mechanismen korrekt implementiert sein, damit ein solches System fehlerfrei und performant funktioniert. Vorab sollte vor allem untersucht werden, ob die Domäne Vorteile aus der Nachverfolgbarkeit der Änderungen ziehen kann. Zudem können natürlich nur Kausalitäten und Abhängigkeiten gelesen werden, wenn diese in den Events enthalten sind. Das Design der Events stellt daher auch eine wichtige Aufgabe dar. Zu guter Letzt sollte noch erwähnt sein das man sich als Entwickler auch erst einmal an die Art und Weise, wie durch den Daten-Stream iteriert wird um anschließend den Zustand zu berechnen, gewöhnen muss.
Dieser Artikel ist ein Blick auf die Spitze des Eisberges Namens Event Sourcings. Ich hoffe es war ein guter, kurzer Einstieg in die Thematik. Sollten sie Diskussionsbedarf, Anregungen oder Kritik haben, freue ich mich über eine Email an: Maximilian.Klimm@pixel.de
Weiterführende Lektüre
Hier noch einige Themen bzw. Quellen die für eine Vertiefung des Themas praktisch sein können.
Event Sourcing
Greg Young
Greg Young ist relativ bekannt in der Softwareentwickler Szene für seine Talks über Event Sourcing und CQRS.
CQRS
CQRS ist ein weiteres Software Pattern, dass die Trennung der lesenden und schreibenden Data Models skizziert. Dieses wird häufig im Zusammenhang mit Event Sourcing gelesen und scheint sich gut mit diesem zu vereinen.